JVM详解
JVM加载过程
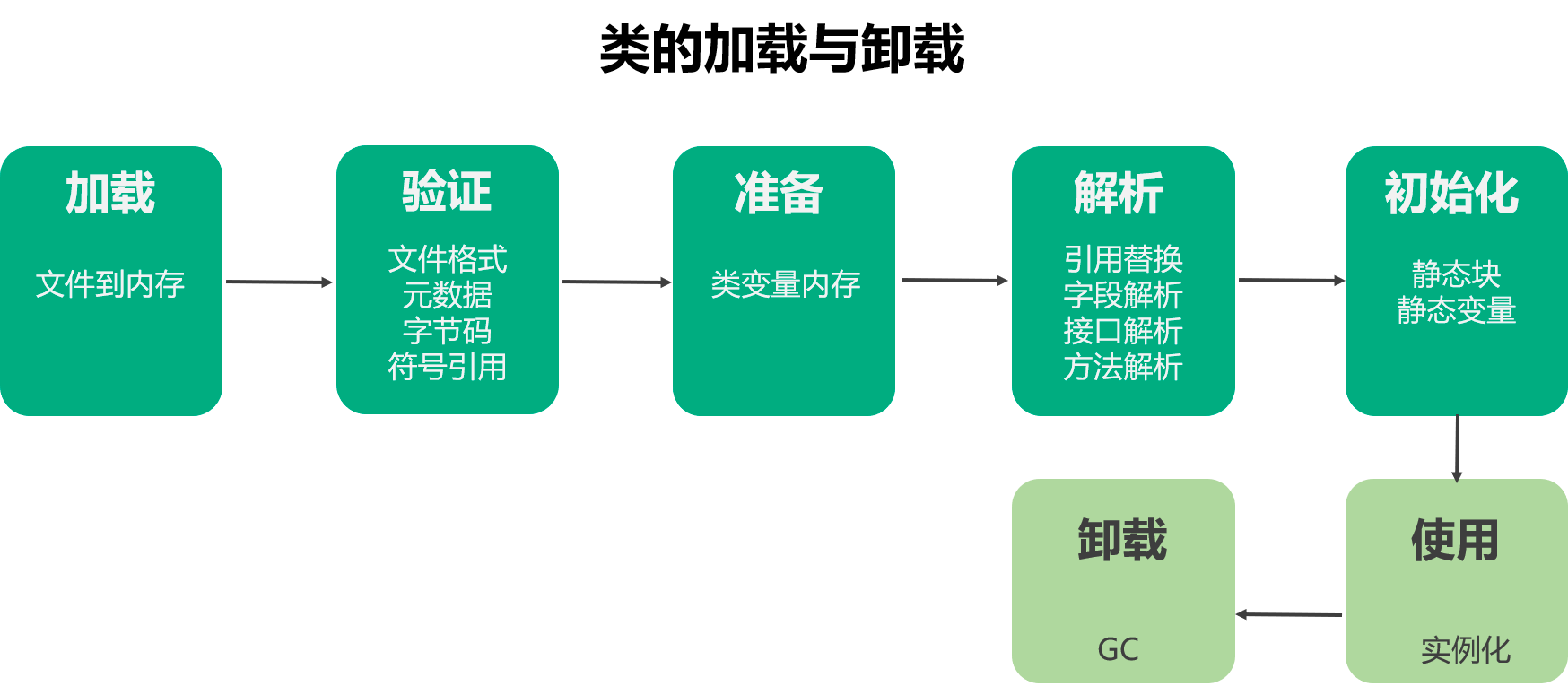
JVM类加载首先会编译java代码为class文件,然后Java虚拟机会加载class文件,类加载具体会有以下的步骤:
- 加载 文件到内存的过程。通过类的完全限定名查找此类的字节码文件,并利用字节码文件创建一个 Class 对象。
- 验证 对类文件内容验证。目的在于确保 Class 文件符合当前虚拟机要求,不会危害虚拟机自身安全。主要包括四种:文件格式验证,元数据验证,字节码验证,符号引用验证。
- 准备 进行内存分配。为类变量也就是类中由 static 修饰的变量分配内存,并且设置初始值。这里要注意,初始值是 0 或者null,而不是代码中设置的具体值,代码中设置的值是在初始化阶段完成的。另外这里也不包含用
final修饰的静态变量,因为final在编译的时候就会分配。 - 解析 主要是解析字段、接口、方法。主要是将常量池中的符号引用替换为直接引用的过程。直接引用就是直接指向目标的指针、相对偏移量等。
- 初始化 主要完成静态块执行与静态变量的赋值。这是类加载最后阶段,若被加载类的父类没有初始化,则先对父类进行初始化。
加载流程如下图:
双亲委派模型【parents delegate】
双亲委派其实真正的翻译应该是父类委托
双亲委派模型其实就是JVM在加载的过程,默认会优先委托给父加载器加载,JVM的内部内置了3个重要的 ClassLoader
- BootstrapClassLoader(启动类加载器):最顶层的加载类,由C++实现,负责加载
%JAVA_HOME%/lib目录下的jar包和类或者或被-Xbootclasspath参数指定的路径中的所有类。 - ExtensionClassLoader(扩展类加载器):主要负责加载目录
%JRE_HOME%/lib/ext目录下的jar包和类,或被 java.ext.dirs 系统变量所指定的路径下的jar包。(jdk9之后使用PlatformClassLoader替代了ExtensionClassLoader) - AppClassLoader(应用程序类加载器): 面向用户的加载器,负责加载当前应用 classpath 下的所有jar包和类。
双亲委派模型在代码层的实现其实就是利用了递归实现的
1 | |
从上面对于 loadClass(String name, boolean resolve)方法的解析来看,可以得出以下2个结论:
1、如果不想打破双亲委派模型,那么只需要重写findClass方法即可
2、如果想打破双亲委派模型,那么就重写整个loadClass方法
我们在进行非classpath路径下的类加载,可以重写 loadClass 方法,指定路径加载, 在调用Class.forName方法,可以指定自己的类加载器
1 | |
JVM常用参数
- -Xms: Java堆内存初始大小
- -Xmx: Java堆内存最大大小
- -Xmn: 新生代大小,减去新生代就是老年代大小
- -XX:PermSize, -XX:MetaspaceSize: 永久代大小
- -XX:MaxPermSize, -XX:MaxMetaspaceSize: 最大永久代大小
- -Xss: 栈内存大小,一般512k或者1M
- -XX:SurvivorRatio: Eden和Survivor的大小比,默认是8
- -XX:MaxTenuringThreshold: 分代回收年龄
- -XX:TargetSurvivorRatio: 动态年龄判断阈值,默认50%
- -XX:CMSInitiatingOccupancyFaction 老年代占用多少比例触发CMS垃圾回收
- -XX:InitiatingHeapOccupancyPercent: G1老年代占据了Region多少比例,会混合回收,默认45%
- -XX:UseCMSCompactAtFullCollection CMS在Full GC之后,stop the world进行碎片整理,默认是打开的
- -XX:CMSFullGCsBeforeCompaction 执行多少Full GC再进行碎片整理,默认0,每次都会执行
- XX:+CMSParallelInitialMarkEnabled:这个参数会在CMS垃圾回收器的“初始标记”阶段开启多线程并发执行
- -XX:+CMSScavengeBeforeRemark:这个参数会在CMS的重新标记阶段之前,先尽量执行一次Young GC,这样可以少扫描一些对象
- -XX:+HeapDumpOnOutOfMemoryError OOM错误的时候导出文件
- -XX:HandlePromotionFailure 内存担保,每次老年代可用空间大于新生代对象或者大于每次晋升老年代的平均对象,就可以Minor GC,1.7以后是默认行为,可以不设置这个参数
- -XX:UseG1GC 指定使用G1垃圾收集器
- -XX:G1MaxNewSizePercent G1新生代最大占比
- -XX:MaxGCPauseMills G1期望停顿时间
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:+HeapDumpPath=/usr/local/app/oom
- -XX:+DisableExplicitGC 禁止手动GC
JVM垃圾收集器选择思路:
- 中小内存,可以使用ParNew+CMS组合
- 大内存,延迟小,使用G1或者ZGC垃圾收集器
进入老年代的情况:
- YGC时,Survivor区不足以存放存活的对象,对象会直接进入到老年代。
- 经过多次YGC后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。
- 动态年龄判定规则,Survivor区中相同年龄的对象,如果其大小之和占到了 Survivor 区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达到默认的分代年龄。
- 大对象:由
-XX:PretenureSizeThreshold启动参数控制,若对象大于此值,就会绕过新生代, 直接在老年代中分配。
OOM常见问题分析
- 高并发场景
高并发QPS一般都在几千几万,这时候会频繁的Yong GC,导致每次会有不少对象进入老年代,触发Full GC,现象就是每几分钟甚至几秒就会卡一次。
这时候就增大新生代内存和增大survivor内存空间,这样可以避免每次回收因为存活对象太多,survivor放不下而频繁进入老年代,此外需要注意,最好每次Full GC就整理一次内存碎片,
避免因为连续空间不够导致的频繁Full GC。
如果不合理的使用了本地缓存一直存数据,不去进行淘汰,也会导致大量的类在老年代,导致频繁Full GC - 大量反射场景
大量反射场景,JVM会生成很多的临时类。比如不合理使用动态代理,就会频繁加载代理类带来Metaspace满而Full GC,进一步导致OOM的问题
G1收集器
- G1默认的是复制算法,效率高,没有内存碎片,把一个Region的存活对象复制到另一个Region
- G1会分为很多相同的Region(默认2048),只在逻辑上分为新生代和老年代,并且能设置为期望停顿时间,G1自动选择最少回收时间和最多回收对象
- 刚开始默认G1新生代为5%,大概100个region,JVM会给新生代增加region,默认最多不超过60%
- G1还是有Eden和Survivor的概念,但是会根据XX:MaxGCPauseMills回收一部分,晋升老年代规则基本不变
- Region角色会动态变化,没有固定的新生代Region,老年代Region
常用JVM参数模版
1 | |
JVM详解
https://jsrdxzw.github.io/2022/02/18/jvm/