I/O 多路复用
阻塞IO
阻塞 I/O,是指进程发起调用后,会被挂起(阻塞),直到收到数据再返回。
如果调用一直不返回,进程就会一直被挂起。因此,当使用阻塞 I/O 时,需要使用多线程来处理多个文件描述符。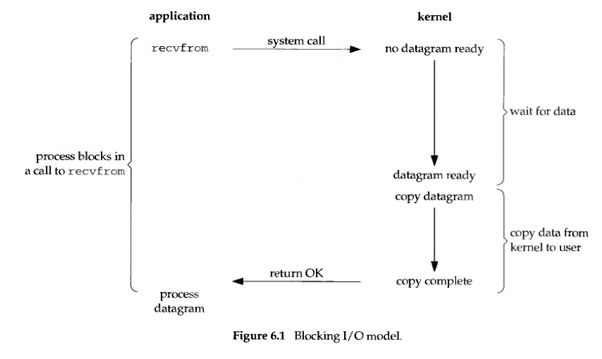
从图中可以看出,从kernel到user操作都被阻塞住了,在Java中,FileInputStream, FileOutputStream以及对Socket的读写
都是基于阻塞IO模型。
非阻塞IO
非阻塞 I/O 不会将进程挂起,调用时会立即返回成功或错误,因此可以在一个线程里轮询多个文件描述符是否就绪。
但是非阻塞 I/O 的缺点是:每次发起系统调用,只能检查一个文件描述符是否就绪。当文件描述符很多时,系统调用的成本很高。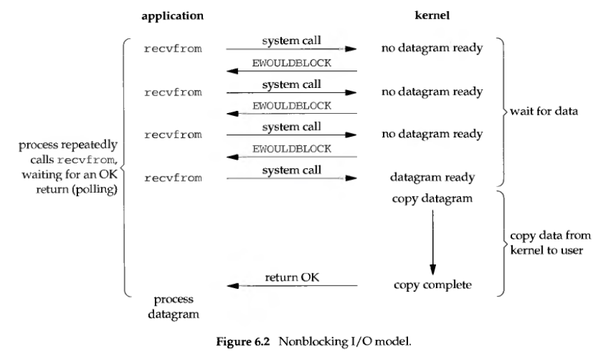
IO多路复用
I/O 多路复用,可以通过一次系统调用,检查多个文件描述符的状态。这是 I/O 多路复用的主要优点,
相比于非阻塞 I/O,在文件描述符较多的场景下,避免了频繁的用户态和内核态的切换,减少了系统调用的开销。
I/O 多路复用相当于将「遍历所有文件描述符、通过非阻塞 I/O 查看其是否就绪」的过程从用户线程移到了内核中,
由内核来负责轮询。
进程可以通过 select、poll、epoll 发起 I/O 多路复用的系统调用,
这些系统调用都是同步阻塞的:如果传入的多个文件描述符中,有任何描述符就绪,则返回就绪的描述符;
否则如果所有文件描述符都未就绪,就阻塞调用进程,直到某个描述符就绪,或者阻塞时长超过设置的 timeout 后再返回。
I/O 多路复用内部使用非阻塞 I/O 检查每个描述符的就绪状态。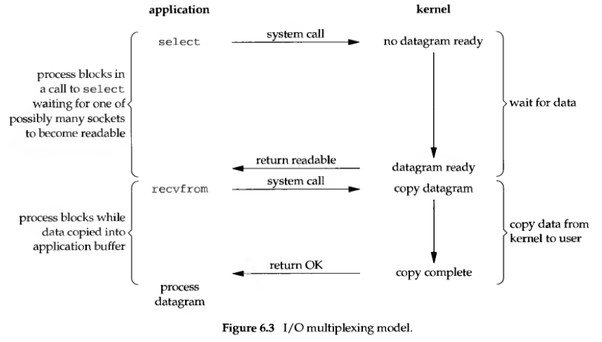
IO多路复用和阻塞IO的区别:
- I/O 多路复用引入了一些额外的操作和开销,比如要调用2次system call
- 用户可以在一个线程内同时处理多个 I/O 请求,而阻塞IO一个线程只能处理一个请求
select
select函数
1 | |
readfds、writefds、errorfds 是三个文件描述符集合, select会分别监听并复值给这三个参数
1 | |
socket的核心源码
主要的源码解释:
- 先声明一个 fd_set 类型的变量 readFDs, fd_set是文件描述符的集合
- 调用 FD_ZERO,将 readFDs 所有位 置0
- 调用 FD_SET,将 readFDs 感兴趣的位 置1,表示要监听这几个文件描述符
- 将 readFDs 传给 select,调用 select
- select 会将 readFDs 中就绪的位 置1,未就绪的位 置0,返回就绪的文件描述符的数量
- 当 select 返回后,调用 FD_ISSET 检测给定位是否为 1,表示对应文件描述符是否就绪
比如进程想监听 1、2、5 这三个文件描述符,就将 readFDs 设置为 00010011,然后调用 select。
如果 fd=1、fd=2 就绪,而 fd=5 未就绪,select 会将 readFDs 设置为 00000011 并返回 2。 - 如果每个文件描述符都未就绪,select 会阻塞 timeout 时长,再返回。这期间,如果 readFDs 监听的某个文件描述符上发生可读事件,则 select 会将对应位置 1,并立即返回。
select的缺点:
- 性能开销大
- 调用 select 时会陷入内核,这时需要将参数中的 fd_set 从用户空间拷贝到内核空间
- 内核需要遍历传递进来的所有 fd_set 的每一位,不管它们是否就绪
- 同时能够监听的文件描述符数量太少。受限于 sizeof(fd_set) 的大小,在编译内核时就确定了且无法更改。一般是 1024,不同的操作系统不相同
poll
poll 和 select 几乎没有区别, 不过在内核会转为链表方式存储,没有最大数量的限制。
epoll
epoll 是对 select 和 poll 的改进,避免了“性能开销大”和“文件描述符数量少”两个缺点。
简而言之,epoll 有以下几个特点:
- 使用红黑树存储文件描述符集合
- 使用队列存储就绪的文件描述符
- 每个文件描述符只需在添加时传入一次;通过事件更改文件描述符状态
- select、poll 模型都只使用一个函数,而 epoll 模型使用三个函数:epoll_create、epoll_ctl 和 epoll_wait。
epoll 实例内部存储:
- 监听列表:所有要监听的文件描述符,使用红黑树
- 就绪列表:所有就绪的文件描述符,使用链表
对于“文件描述符数量少”,select 使用整型数组存储文件描述符集合,而 epoll 使用红黑树存储,数量较大。
对于“性能开销大”,epoll_ctl 中为每个文件描述符指定了回调函数,并在就绪时将其加入到就绪列表,因此 epoll 不需要像 select 那样遍历检测每个文件描述符,只需要判断就绪列表是否为空即可。这样,在没有描述符就绪时,epoll 能更早地让出系统资源。
三者对比
- select:调用开销大(需要复制集合);集合大小有限制;需要遍历整个集合找到就绪的描述符
- poll:采用链表的方式存储文件描述符,没有最大存储数量的限制,其他方面和 select 没有区别
- epoll:调用开销小(不需要复制);集合大小无限制;采用回调机制,不需要遍历整个集合
异步IO
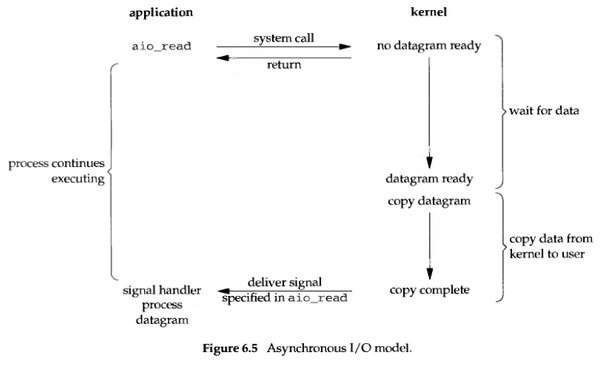
异步IO就是在内核中完成操作,完成才通知到客户端