raft算法
raft算法简介
raft算法是Paxos算法的工程实现,主要特点就是通过较为简单的算法实现分布式系统的数据一致性和高可用,
Raft通过选举一个领导人,然后给予他全部的管理复制日志的责任来实现一致性。
Raft算法中任何服务器都可以扮演下面的角色之一:
- 领导者(leader): 处理客户端交互,日志复制等动作,一般一次只有一个领导者
- 候选者(candidate): 候选者就是在选举过程中提名自己的实体,一旦选举成功,则成为领导者
- 跟随者(follower): 类似选民,完全被动的角色,这样的服务器等待被通知投票
他们之间的身份变化如下图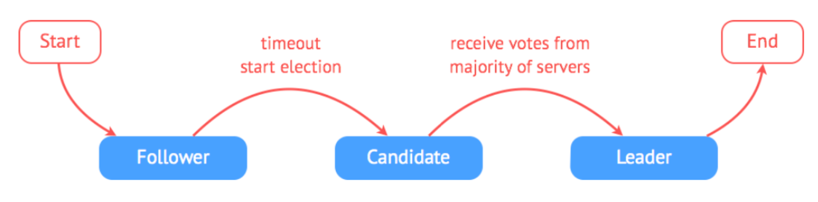
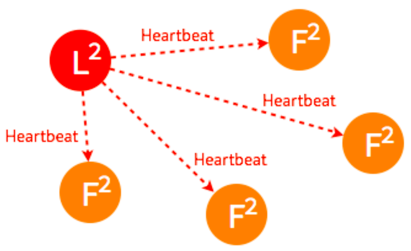
leader选举
- 初始状态下集群中的所有节点都处于
follower状态
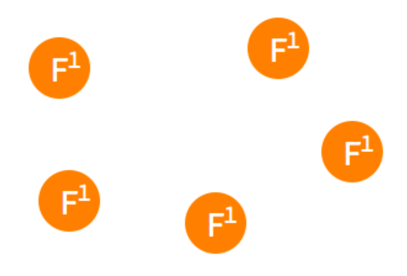
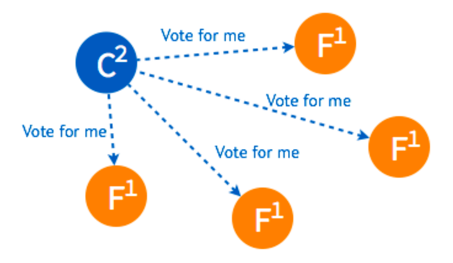
- 某一时刻,其中的一个
follower由于没有收到leader的heartbeat率先发生election timeout进而发起选举
- 只要集群中超过半数的节点接受投票,
candidate节点将成为即切换leader状态
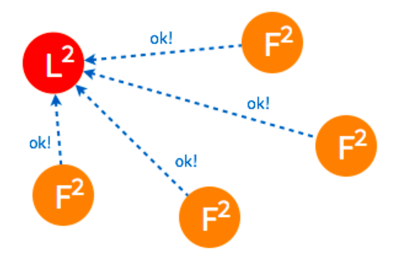
- 成为
leader节点之后,leader将定时向follower节点同步日志并发送heartbeat
日志复制
raft协议的 log replication 有点类似 2PC ,但是不同的是raft只要求大多数节点的回复即可,raft保证的是最终一致性
leader会不断尝试给follower发log entries,直到所有节点的log entries都相同。
Raft 协议要求投票只能投给拥有最新数据的节点, 保证了在同步log的时候leader挂掉,重新选举leader的时候,数据不丢失
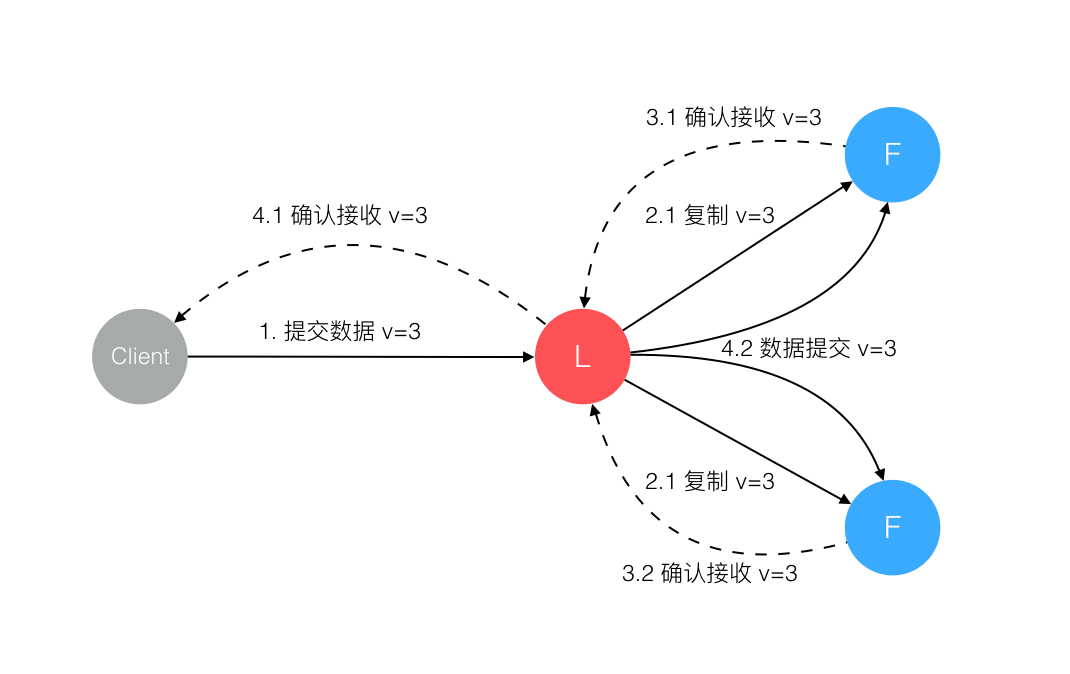
主要步骤如下:
- 客户端的每一个请求都包含被复制状态机执行的指令。
- leader把这个指令作为一条新的日志条目添加到日志中,然后并行发起 RPC 给其他的服务器,让他们复制这 条信息。
- 跟随者响应ACK,如果 follower 宕机或者运行缓慢或者丢包,leader会不断的重试,直到所有的 follower 最终 都复制了所有的日志条目。
- 通知所有的Follower提交日志,同时领导人提交这条日志到自己的状态机中,并返回给客户端。
- 如果committed状态后client未收到leader响应,则client会重新发送请求,需要做幂等保证一致性。
- 如果leader在发送commit给从节点之前挂掉,就会导致从节点存在
uncommitted log,这时候会重新选举,
按照raft协议,新leader会包含之前leader的最新log,并且在新的term下,commit新的entry时,就会一并把前leader前term的前entry也提交了,于是所有状态机就一致了
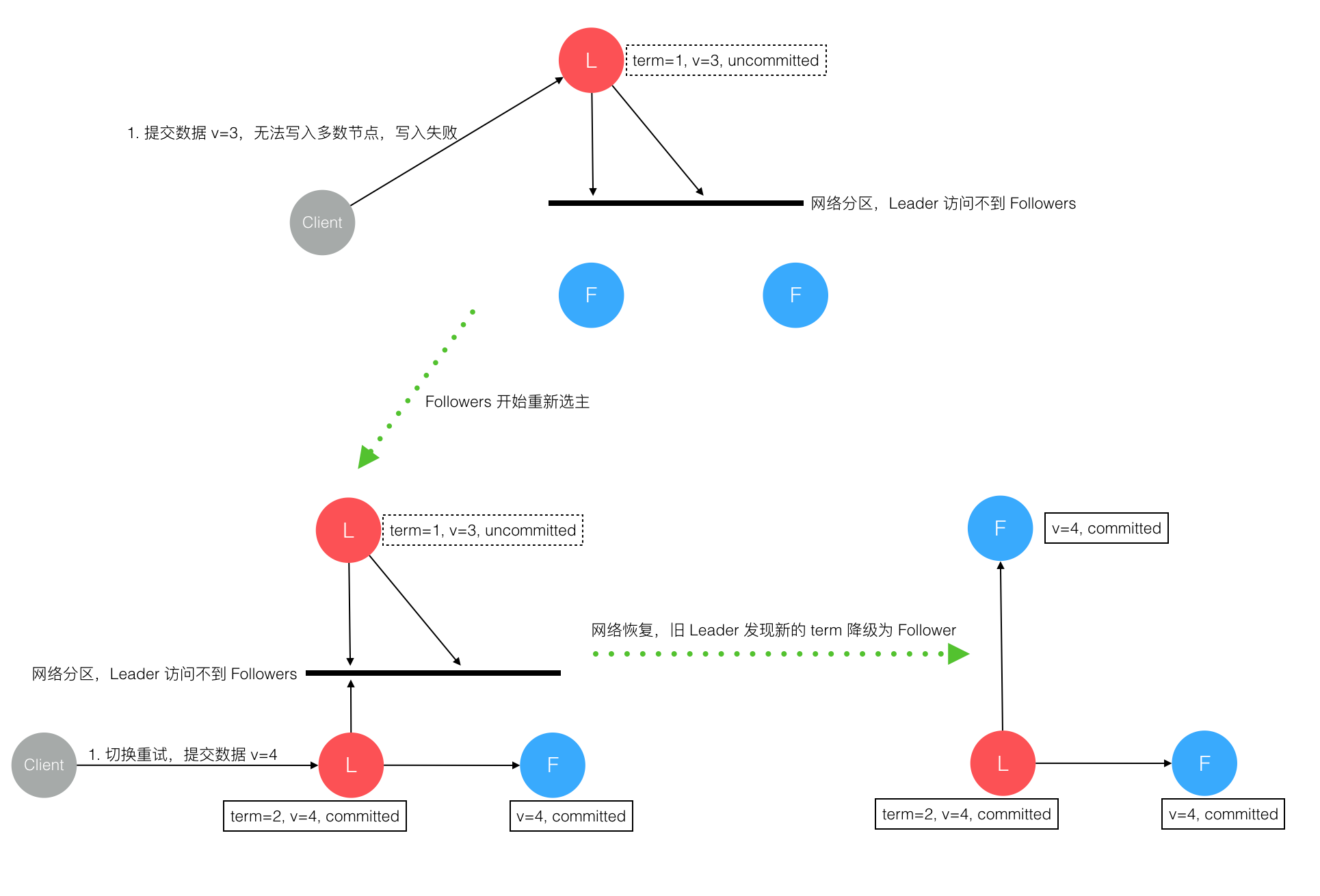
脑裂情况
raft也可以保证在脑裂情况保证数据的一致性
参考资料
raft算法
https://jsrdxzw.github.io/2021/07/28/raft/