在数据库集群模式中,往往不能使用自增id,这时候可以在业务端生成全局唯一id。主要的方法有三种
UUID
直接使用jdk提供的UUID,优点是简单,缺点是非自增,无规律
snowflake算法
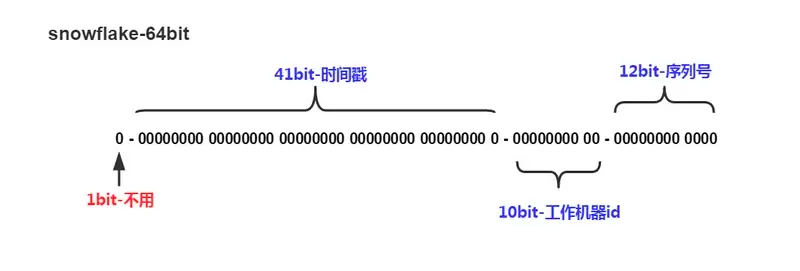
雪花算法主要结构如下
- 1 位,不用。二进制中最高位为 1 的都是负数,但是我们生成的 id 一般都使用整数,所以这个最高位固定是
0
- 41 位,用来记录时间戳(毫秒), 理论上可以支持69年左右
- 10 位,用来记录集群id和工作机器id
- 可以部署在
2^10 = 1024 个节点,包括 5 位 datacenterId 和 5 位 workerId
- 12 位序列号,用来记录同毫秒内产生的不同 id, 一毫秒同一个机器可以产生4096个id
SnowFlake 可以保证:
同一台服务器所有生成的 id 按时间趋势递增
整个分布式系统内不会产生重复 id(因为有 datacenterId 和 workerId 来做区分)
依赖机器时钟,需要做时钟同步
主要的算法实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",
lastTimestamp - timestamp));
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
|
具体的源码可以参考这里 雪花算法源码
借助Redis的Incr命令获取全局唯⼀ID
Redis可以保证原子性提供全局id,也是一个推荐的做法
1
2
3
4
5
6
7
8
9
| Jedis jedis = new Jedis("127.0.0.1", 6379);
try {
long id = jedis.incr("id");
System.out.println("从redis中获取的分布式id为:" + id);
} finally {
if (null != jedis) {
jedis.close();
}
}
|